我们需要一些指标, 评估学习得到的模型的好坏, 并针对具体的问题, 选择重视哪几项指标.
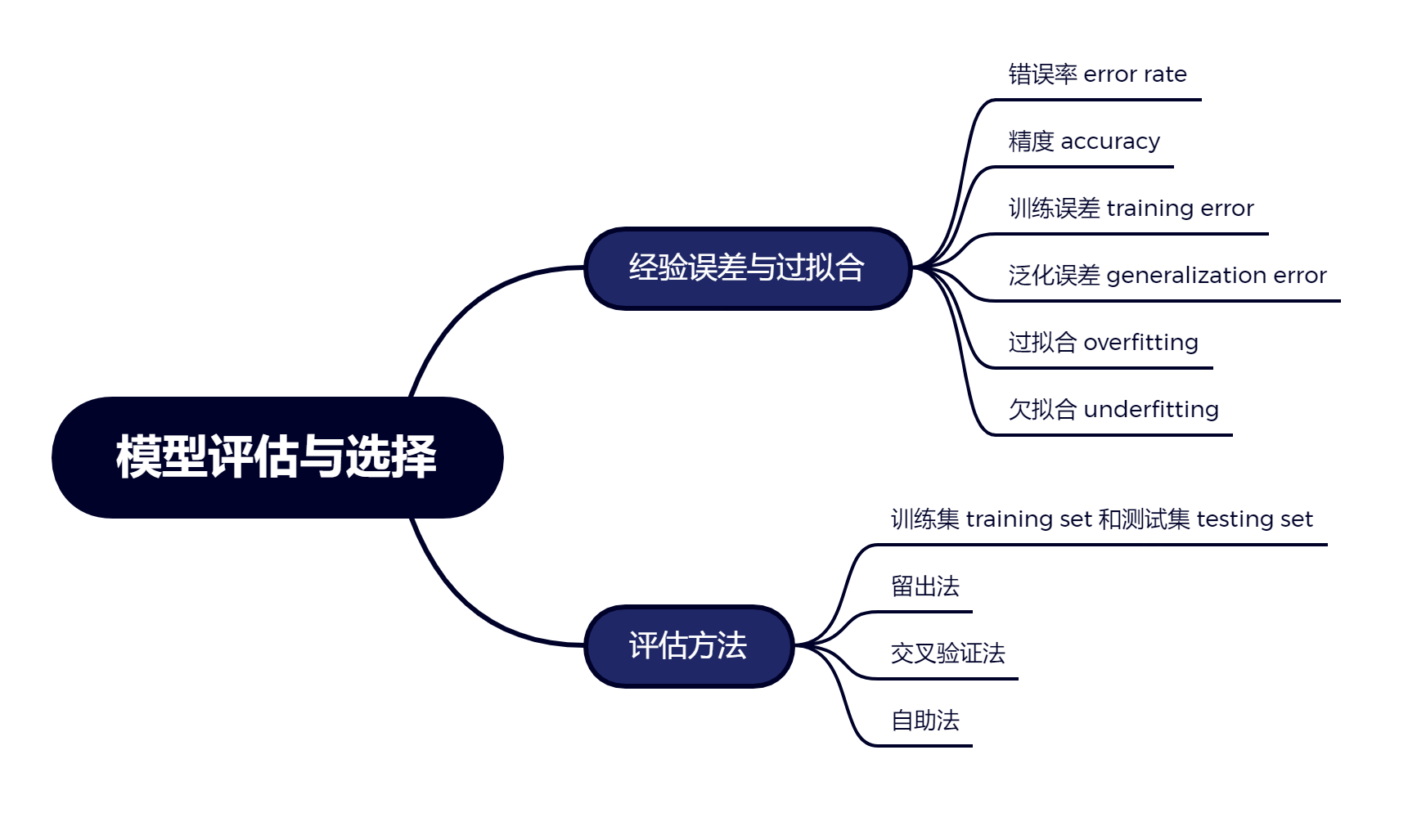
2.1 经验误差与过拟合
通常把分类错误的样本数占样本总数的比例称为”错误率“(error rate). 如果在 $m$ 个样本中有 $a$ 个样本分类错误, 则错误率 $E=a/m$; 相应的, $1-a/m$ 称为”精度“(accuracy), 即”精度=1-错误率”.
学习器的实际预测输出与样本的真实输出之间的差异称为”误差“(error), 学习器在训练集上的误差称为”训练误差“(training error)或”经验误差“(empirical error), 在新样本上的误差称为”泛化误差“(generalization error).
学习的目的是希望模型在未见过的新样本上表现得很好, 因此我们希望学习算法能从训练样本中学得所有潜在样本的”普遍规律”. 但如果学习算法把训练样本学习得”太好”了, 便可能把训练样本自身的一些特征当作所有潜在样本的特征, 而这些特征实际上并不属于所有潜在样本, 这就会导致模型的泛化能力下降. 这种现象在机器学习中称为”过拟合“(overfitting). 与之相对的是”欠拟合“(underfitting), 指对训练样本的一般性质尚未学好.
过拟合的具体表现为, 模型的训练误差很小, 泛化训练误差很大. 欠拟合则是模型的训练误差和泛化误差都较大.
“模型选择“(model selection)问题: 理想的方案是对候选模型的泛化误差进行评估, 然后选择泛化误差最小的那个模型.
2.2 评估方法
可通过实验测试来对模型的泛化误差进行评估并进而做出选择. 使用一个”测试集“(testing set)来测试学习器对新样本的判别能力, 然后以测试集上的”测试误差“(testing error)作为泛化误差的近似. 这样的测试集有时也成为”验证集“(validation set).
测试集应尽量与训练集互斥, 使得测试集相对训练集”较新”, 从而更有效地验证模型的泛化能力.
假设现有数据集 $D={(\boldsymbol{x}_1,y_1),(\boldsymbol{x}_2,y_2),…,(\boldsymbol{x}_m,y_m)}$ , 对其进行适当的处理, 从中产生出训练集 $S$ 和测试集 $T$, 分别用于训练和测试.
2.2.1 留出法
“留出法“(hold-out)直接将数据集 $D$ 划分为两个互斥的集合, 其中一个集合作为训练集 $S$ , 另一个作为测试集 $T$ .即
\[D=S\cup T, S\cap T= \varnothing\]在 $S$ 上训练出模型后,用 $T$ 来评估其测试误差, 作为对泛化误差的近似.
训练/测试集的划分要尽可能保持数据分布的一致性, 避免因数据划分过程中引入额外的偏差对最终结果产生影响. 从采样(sampling)的角度来看待数据集的划分过程, 保留类别比例的采样方式通常称为”分层采样“(stratified sampling).
单次使用留出法得到的估计结果往往不够稳定可靠, 在使用留出法时, 一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果.
2.2.2 交叉验证法
“交叉验证法“(cross validation)先将数据集 $D$ 划分为 $k$ 个大小相似的互斥子集, 即 $D=D_1\cup D_2\cup … \cup D_k, D_i\cap D_j=\varnothing(i\neq j)$ . 每个子集 $D_i$ 都尽可能保持数据分布的一致性, 即从 $D$ 中通过分层采样得到. 然后, 每次用 $k -1$ 个子集的并集作为训练集, 余下的那个子集作为测试集; 这样就可获得 $k$ 组训练/测试集, 从而可进行 $k$ 此训练和测试, 最终返回的是这 $k$ 个测试结果的均值.
交叉验证法评估结果的稳定性和保真性在很大程度上取决于 $k$ 的取值, 因此将其称为”$k$ 折交叉验证“(k-fold cross validation).
$k$ 折交叉验证通常要随机使用不同的划分重复 $p$ 次, 最终的评估结果是这 $p$ 次 $k$ 折交叉验证的结果.
假设数据集 $D$ 中有 $m$ 个样本, 令 $k=m$, 则得到交叉验证法的一个特例: 留一法(Leave-One-Out, 简称 LOO). 因为 $m$ 个样本只有唯一的方式被划分为 $m$ 个子集, 因此留一法不受随机样本划分的影响. 又因为留一法使用的数据集与初始数据集相比只少了一个样本, 被实际评估的模型与期望评估的用 $D$ 训练出的模型很相似. 但在数据集较大时, 训练 $m$ 个模型的计算开销可能是难以忍受的.
2.2.3 自助法
留出法和交叉验证法中保留了一部分样本用于测试, 必然会引入一些因训练样本规模不同而导致的估计偏差. 而留一法的计算复杂度可能无法接受.
“自助法“(bootstrapping) 是一个比较好的解决方案. 给定包含 $m$ 个样本的数据集 $D$, 对它进行采样产生数据集 $D’$ : 每次随机从 $D$ 中挑选一个样本, 将其拷贝放入 $D’$ , 然后再将该样本放回初始数据集中, 使得该样本在下次采样时仍可能被采到; 这个过程重复执行 $m$ 次后, 就得到了包含 $m$ 个样本的数据集 $D’$. 样本在 $m$ 次采样中始终不被采到的概率是 $\left(1-1/m\right)^m$ , 取极限得
\[\lim_{m\to\infty}\left(1-\frac{1}{m}\right)^m=\frac{1}{e}\approx 0.368\]即通过自主采样, 初始数据集 $D$ 中约有 $36.8\%$ 的样本未出现在采样数据集 $D’$ 中. 于是可将 $D’$ 用作训练集, $D\setminus D’$ 用作测试集; 这样, 实际评估的模型与期望评估的模型都使用 $m$ 个训练样本, 而我们仍有数据总量约 $1/3$ 的、没在训练集中出现的样本用于测试. 这样的测试结果, 亦称“包外估计”(out-of-bag estimate).
自助法在数据集较小, 难以有效划分训练/测试集时很有用. 然而, 自助法产生的数据集改变了初始数据集的分布, 会引入估计偏差.
2.2.4 调参与最终模型
大多数学习算法都有些参数(parameter)需要设定, 如学习率(learning rate)等. 参数配置不同, 学得模型的性能往往有显著差别. 因此,在进行模型评估与选择时, 除了要对适用学习算法进行选择, 还需对算法参数进行设定, 这就是通常所说的”参数调节“或简称”调参 “(parameter tuning).
给定包含 $m$ 个样本的数据集 $D’$, 在模型评估与选择过程中由于需要留出一部分数据进行评估测试, 事实上我们只使用了一部分数据训练模型. 因此, 在模型选择完成后, 学习算法和参数配置已选定, 此时应该用数据集 $D$ 重新训练模型. 这个模型在训练过程中使用了所有 $m$ 个样本,这才是我们最终提交给用户的模型.
通常把学得模型在实际使用中遇到的数据称为测试数据,为了加以区分,模型评估与选择中用于评估测试的数据集常称为”验证集” (validation set), 即上文所说的”测试集”. 今后将已有数据集外的新样本称作”测试集”.