2.3 性能度量
性能度量(performance measure)是衡量模型泛化能力的评价标准, 性能度量反应了任务需求.
在预测任务中, 给定样例集 $D={(\boldsymbol{x}_1,y_1),(\boldsymbol{x}_2,y_2),…,(\boldsymbol{x}_m,y_m)}$ , 其中 $y_i$ 是示例 $\boldsymbol{x}_i$ 的真实标记. 要评估模型 $f$ 的性能, 就要把学习器预测结果 $f(\boldsymbol{x}_i$) 与真实标记 $y$ 进行比较. 用来衡量 $f(\boldsymbol{x}_i$) 和 $y$ 的差异的函数称为”损失函数“(Loss function).
例如, 回归任务最常用的性能量度是”均方误差“(mean squared error):
\[E(f;D)=\frac{1}{m}\sum_{i=1}^{m}(f(\boldsymbol{x}_i)-y_i)^2\]对于数据分布 $D$ 和概率密度函数 $p(\cdot)$ , 均方误差可描述为
\[E(f;\mathcal{D})=\int_{x\sim \mathcal{D}}(f(\boldsymbol{x})-y)^2p(\boldsymbol{x})\text{d}\boldsymbol{x}\]2.3.1 错误率和精度
错误率是分类错误的样本数占总样本数的比例, 精度则是分类正确的样本数占样本总数的比例. 对样例集 $D$, 分类错误率定义为
\[E(f;D)=\frac{1}{m}\sum_{i=1}^m\mathbb{I}(f(\boldsymbol{x}_i\neq y_i)).\]其中 $\mathbb{I}(\cdot)$ 是指示函数, 当 $\cdot$ 为 true 时, $\mathbb{I}(\cdot)$ 为 $1$.
精度定义为
\[\text{acc}(f;D)=\frac{1}{m}\sum_{i=1}^{m}\mathbb{I}(f(\boldsymbol{x}_i= y_i))=1-E(f;D)\]对于数据分布 $D$ 和概率密度函数 $p(\cdot)$
\[E(f;\mathcal{D})=\int_{x\sim \mathcal{D}}\mathbb{I}(f(\boldsymbol{x}\neq y))p(\boldsymbol{x})\text{d}\boldsymbol{x}.\] \[\text{acc}(f;\mathcal{D})=\int_{x\sim\mathcal{D}}\mathbb{I}(f(\boldsymbol{x}= y))p(\boldsymbol{x})\text{d}\boldsymbol{x}.=1-E(f;\mathcal{D}).\]2.3.2 查准率, 查全率与 $F1$
错误率和精度并不能满足所有任务需求. 以挑出好西瓜的问题为例, 如果我们关心的是”挑出的西瓜中有多少比例是好瓜”, 这个比例可以表示为 “挑出的真好瓜 / (挑出的真好瓜+挑出的假好瓜)”, 这称为”查准率“(precision); 如果我们关心的是”所有好瓜中有多少被挑了出来”, 这个比例可以表示为 “挑出的真好瓜 / (挑出的真好瓜 + 没挑出的真好瓜)”, 这称为”查全率“(recall).
对于二分类问题, 可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive), 假正例(false positive), 真反例(true negative), 假反例(false negative), 令 $TP, FP, TN, FN$ 分别表示其对应的样例数, 显然 $TP+FP+TN+FN=$ 样例总数.
以挑好西瓜问题为例, 真正例即挑出的好西瓜, 假正例即挑出的瓜中的坏西瓜, 真反例即没挑出来的坏西瓜, 假反例即没挑出的好西瓜.
这样的分类结果的”混淆矩阵“(confusion matrix)可表示为
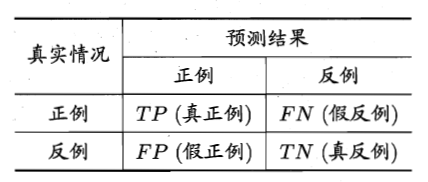
(图片来源于《机器学习》)
查准率 $P$ 定义为
\[P=\frac{TP}{TP+FP}\]查全率 $R$ 定义为
\[R=\frac{TP}{TP+FN}\]可以看出, 查准率和查全率是一对矛盾的度量. 一般来说, 查准率高时, 查全率往往偏低; 而查全率高时, 查准率往往偏低. 又以西瓜为例, 为了挑出更多的好瓜, 即查全率 $R$ 尽可能高, 此时挑出的坏瓜可能就越多, 查准率 $P$ 变低.
显然, 如果我们将所有样本全部视为正例, 查全率必然保持较高, 而查准率必然偏低. 因此在评估模型时, 有时需要同时考虑查准率和查全率.
很多情形下, 模型的预测结果为一个 $0\sim 1$ 的实数值. 以分类好坏西瓜为例, 可以让模型预测这个瓜为好瓜的可能性, 该可能性表示为 $0\sim 1$ 的概率 $p$. 我们可以定义一个阙值 $b$, 当 $p>b$ 时, 认为它是好瓜. 由此, 可以根据模型的预测结果对我们已有的西瓜进行排序, 排在前面的是模型认为”最可能”是好瓜的西瓜, 排在后面的则是模型认为”最不可能”是好瓜的西瓜.
假设排序的结果如下:
\[\lbrace\text{坏瓜}^{(0.15)},\text{坏瓜}^{(0.18)},\text{坏瓜}^{(0.35)},\text{好瓜}^{(0.64)},\text{坏瓜}^{(0.71)},\text{好瓜}^{(0.87)}\rbrace\]其中, “好瓜”、”坏瓜”为实际上该西瓜的好坏, 其上标为模型预测其为好瓜的概率. 按概率从小到大的顺序, 把每个西瓜对应预测出的概率作为阙值 $b$ , 大于等于 $b$ 的西瓜视为好瓜, 每次计算出当前的查准率、查全率. 例如, $b=0.15$ 时, 查准率 $=1/3$, 查全率为 $=1$; $b=0.71$ 时, 查准率 $=1/2$, 查全率为 $=1/2$. 以查准率为纵轴、查全率为横轴作图, 就得到了查准率-查全率曲线, 简称 “ $\text{P-R}$ “曲线.
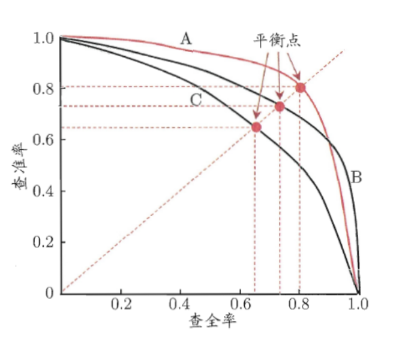
(上图来源于《机器学习》, 且与上例无关)
若一个模型的 $\text{P-R}$ 曲线被另一个模型的曲线完全“包住”, 则可断言后者的性能优于前者, 若两个模型的 $\text{P-R}$ 曲线发生了交叉, 可以比较曲线下的面积来比较两个模型的性能高低. 但曲线的面积不容易估算, 还有一些其他的综合考虑查准率、查全率的性能度量. 如平衡点.
“平衡点“(Break-Event Point, 简称 BEP) 是”查准率=查全率”时的取值. 可以认为拥有较大平衡点的模型较优.
更常用的评估标准是 $F1$ 度量:
$F1$ 是基于查准率与查全率的调和平均定义的:
\[\frac{1}{F1}=\frac{1}{2}\cdot\left(\frac{1}{P}+\frac{1}{R}\right)\] \[F1=\frac{2\times P\times R}{P+R}=\frac{2\times TP}{\text{样例总数}+TP-TN}\]在现实应用中, 对查准率和查全率的重视程度有所不同. $F1$ 度量的一般形式 $F_\beta$ 定义为
\[\frac{1}{F_\beta}=\frac{1}{1+\beta^2}\cdot\left(\frac{1}{P}+\frac{\beta^2}{R}\right)\] \[F_\beta=\frac{(1+\beta^2)\times P\times R}{(\beta^2\times P)+R}\]$\beta >0$ 度量了查全率对查准率的相对重要性. $\beta=1$ 时退化为标准的 $F1$ ; $\beta>1$ 时查全率有更大影响; $\beta<1$ 时查准率有更大影响.
很多时候我们有多个二分类混淆矩阵, 例如进行多次训练/测试, 每次得到一个混淆矩阵; ;或是在多个数据集上进行训练/测试, 希望估计算法的”全局”性能, 便希望能在 $n$ 个二分类混淆矩阵上综合考察查准率和查全率.
一种做法是先在个混淆矩阵上分别计算出查准率和查全率, 记为 $(P_1, R_1), (P_2, R_2),\cdots,(P_n, R_n)$ 再计算平均值, 这样就得到”宏查准率”($\text{macro-}P$)、”宏查全率”($\text{macro-}R$)和相应的”宏$F1$”($\text{macro-}F1$):
\[\text{macro-}P=\frac{1}{n}\sum_{i=1}^{n}P_i,\\ \text{macro-}R=\frac{1}{n}\sum_{i=1}^{n}R_i,\] \[\text{macro-}F1=\frac{2\times\text{macro-}P\times\text{macro-}R}{\text{macro-}P+\times\text{macro-}R}\]还可以先将各混淆矩阵的对应元素进行平均, 得到 $TP, FP, TN, FN$ 的平均值, 分别记为 $\overline{TP}, \overline{FP}, \overline{TN}, \overline{FN}$ , 再基于这些平均值计算出”微查准率”($\text{micro-}P$)、”微查全率”($\text{micro-}R$)和”微$F1$”($\text{micro-}F1$).
\[\text{macro-}P=\frac{\overline{TP}}{\overline{TP}+\overline{FP}}\\ \text{macro-}R=\frac{\overline{TP}}{\overline{TP}+\overline{FN}}\] \[\text{micro-}F1=\frac{2\times\text{micro-}P\times\text{micro-}R}{\text{micro-}P+\times\text{micro-}R}\]2.3.3 ROC 与 AUC
上文中提到的阙值, 即将测试样本排序分类, 大于阙值则分为正类, 否则为反类. 这个阙值即为分类阙值(threshold). 分类过程相当于在这个排序中以某个”截断点“(cut point)将样本分为两部分.
在不同的应用任务中, 我们可根据任务需求来采用不同的截断点, 例如若我们更重视”查准率”, 则可选择排序中靠前的位置进行截断; 若更重视查全率”, 则可选择靠后的位置进行截断. 因此, 排序本身的质量好坏, 体现了综合考虑学习器在不同任务下的”期望泛化性能”的好坏. ROC 曲线则是从这个角度出发来研究学习器泛化性能.
ROC 全称为”受试者工作特征“(Receiver Operating Characteristic)曲线. 与 $\text{P-R}$ 曲线类似, 根据模型的预测结果对样例进行排序, 按此顺序逐个把样本作为正例进行预测, 每次计算出两个重要的值, 分别是”真正例率“(True Positive Rate, 简称 TPR) 和”假正例率“(False Positive Rate, 简称 FPR). 两者分别定义为
\[\text{TPR}=\frac{TP}{TP+FN}, \\ \text{FPR}=\frac{FP}{TN+FP}\]真正例率可理解为: 已知样本为正例, 预测结果为正例的概率. 假正例率可理解为: 已知样本为负例, 预测结果为正例的概率.
以 TPR 为纵轴, FPR 为横轴作图, 就得到了”ROC 曲线”. 显示 ROC 曲线的图称为”ROC 图”. 我们希望的得到的”理想模型”是 $\text{TPR}=1, \text{FPR}=0$, 即将所有正例排在了所有反例之前.
现实任务中通常是利用有限个测试样例来绘制 ROC 图, 此时仅能获得有限个坐标对, 无法产生光滑的 ROC 曲线.
进行学习器比较时, 与 $\text{P-R}$ 图类似, 若一个模型的 ROC 曲线被另一个模型的曲线完全”包住”, 则可断言后者的性能优于前者. 较为合理的判据是比较 ROC 曲线下的面积, 即 AUC(Area Under ROC Curve).
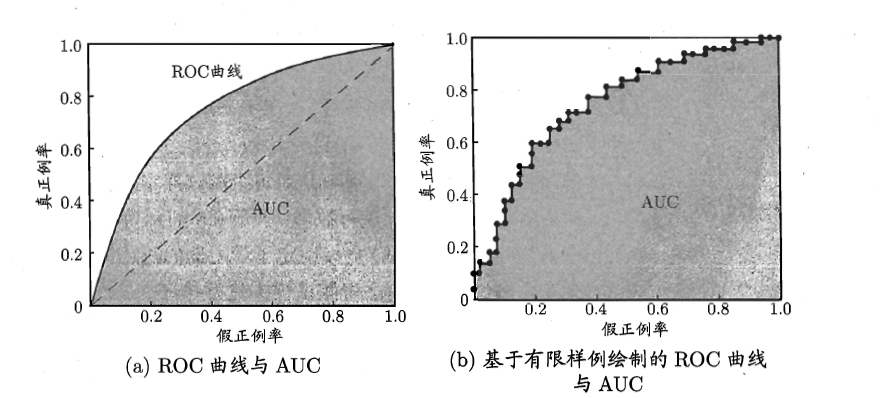
(图片来源于《机器学习》)
2.3.4 代价敏感错误率与代价曲线
在现实应用中, 同一个任务中不同类型的错误会造成不同的影响. 例如在医疗诊断中, 将健康人诊断为患者仅仅是增加了后续进一步治疗的麻烦, 但把患者诊断为健康人则会错失拯救生命的机会.
为权衡不同类型错误所造成的不同损失, 可为错误赋予”非均等代价“(unequal cost).
以二分类问题为例, 可根据任务的领域知识设定一个”代价矩阵“(cost matrix):
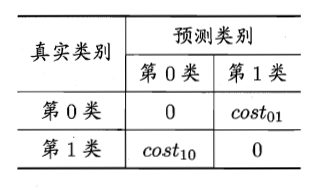
(图片来源于《机器学习》)
若将第 0 类判别为第 1 类所造成的损失更大, 则令 $cost_{01}>cost_{10}$ ; 损失程度相差越大, $cost_{01}$ 和 $cost_{10}$ 的比值就越大.
在非均等代价的条件下, 我们所希望的是最小化”总体代价“(total cost), 而不是简单地最小化错误次数. 令上表中的第 0 类作为正类, 第 1 类作为反类, 令 $D^+$ 与 $D^{-}$ 分别代表样例集 $D$ 中的正例子集和反例子集. 用 $p$ 表示样例为正例的概率, 即 $p=\vert D^+\vert/\vert D\vert$.
考虑上文定义过的真正例率, 将其用条件概率的形式给出, 则真正例率可表示为
\[\text{TPR}=P(0\vert D^+)\]其中 $0$ 代表预测结果为正类, 已知样例为正例. 类似地, 假正例率、真反例率和假反例率可分别表示为
\[\text{FPR}=P(0\vert D^{-}),\quad \text{TNR}=P(1\vert D^{-}),\quad \text{FNR}=P(0|D^{-})\]于是可以给出样例与预测结果的联合概率分布 $P(\text{预测结果}, \text{已知样例类别})$
\[\begin{align} &P(0, D^{+})=P(0\vert D^{+})P(D^{+})=\text{TPR}\times p\\ &P(0, D^{-})=P(0\vert D^{-})P(D^{-})=\text{FPR}\times(1-p)\\ &P(1, D^{-})=P(1\vert D^{-})P(D^{-})=\text{TNR}\times(1-p)\\ &P(1, D^{+})=P(1\vert D^{+})P(D^{+})=\text{FNR}\times p\\ \end{align}\]由此我们能计算期望代价为
\[E(f;D;cost)=cost_{00}\times P(0,D^{+})+cost_{01}\times P(1,D^{+})+cost_{10}\times P(0,D^{-})+cost_{11}\times P(1,D^{-})\]由于 $cost_{00}=cost_{11}=0$, 所以
\[E(f;D;cost)=cost_{01}\times p\times \text{FNR}+cost_{10}\times (1-p)\times \text{FPR}\]上式还可以做如下变形: 如果记 $\vert D\vert =m, \vert D^{+}\vert=m^{+}, \vert D^{-} \vert = m^{-}$, 则
\[p=\frac{m^{+}}{m},\quad 1-p=\frac{m^{-}}{m}\] \[\text{FNR}=\frac{\displaystyle\sum_{\boldsymbol{x}_i\in D^{-}}\mathbb{I}(f(\boldsymbol{x}_i\neq y_i))}{m^{-}},\quad \text{FPR}=\frac{\displaystyle\sum_{\boldsymbol{x}_i\in D^+}\mathbb{I}(f(\boldsymbol{x}_i\neq y_i))}{m^+}\] \[E(f;D;cost)=\frac{1}{m}\left(\sum_{\boldsymbol{x}_i\in D^+}\mathbb{I}(f(\boldsymbol{x}_i\neq y_i))\times cost_{01}+\sum_{\boldsymbol{x}_i\in D^-}\mathbb{I}(f(\boldsymbol{x}_i\neq y_i))\times cost_{10}\right)\]上式即书中的”代价敏感“(cost-sensitive)错误率.
继续考虑式子 $E(f;D;cost)=cost_{01}\times p\times \text{FNR}+cost_{10}\times (1-p)\times \text{FPR}$. 如果所有的正例都被预测为反类, 所有的负例都被预测为正类, 此时 $\text{FPR}=\text{FNR}=1$, $E(f;D;cost)$ 最大. 因此可以将其取值范围归一化为 $[0,1]$, 操作方法即将其除以最大值:
\[cost_{norm}=\frac{\text{FNR}\times p\times cost_{01}+\text{FPR}\times (1-p)\times cost_{10}}{p\times cost_{01}+(1-p)\times cost_{10}}\]在非均等代价的条件下, ROC 曲线不能直接反映出学习器的期望总体代价, 而”代价曲线”(cost curve) 则可达到该目的. 代价曲线图的横轴是取值为 $[0,1]$ 的正例概率代价
\[P(+)cost=\frac{p\times cost_{01}}{p\times cost_{01}+(1-p)\times cost_{10}}\]其中 $p$ 是样例为正例的概率. 观察上式, 在均等代价的条件下, 即 \(cost_{01}=cost_{10}\) , \(P(+)_{cost}=p\). 如果将上式代入 \(cost_{norm}\), 得到
\[cost_{norm}=\text{FNR}\times P(+)_{cost}+\text{FPR}\times (1-P(+)_{cost})\]观察上式, 若以 \(P(+)_{cost}\) 为自变量, 当 \(P(+)_{cost}=0\) 时, \(cost_{norm}=\text{FPR}\), 当 \(P(+)_{cost}=1\) 时, \(cost_{norm}=\text{FNR}\). 所以, $cost_{norm}$ 在平面直角坐标系中是一条从 \((0,\text{FPR})\) 到 \((1,\text{FNR})\) 的一条直线段.
回顾上文提到的 ROC 曲线, 曲线上每一点是 $(\text{FPR},\text{TPR})$, 据此我们可以计算 $(\text{FPR},\text{FNR})$ . 于是 ROC 曲线上每一点对应了一条 $cost_{norm}$ 线段. 将从 ROC 曲线得到的每一条 $cost_{norm}$ 线段作在同一个平面直角坐标系中, 这个坐标系称为”代价平面”.
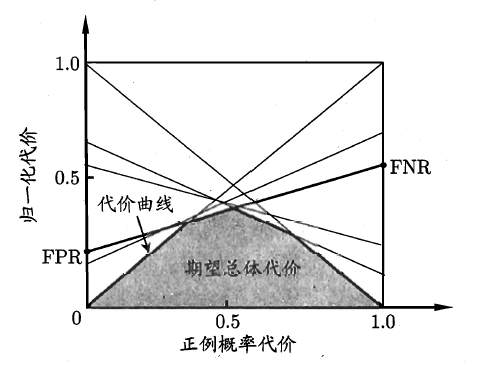
(图片来源于《机器学习》)
所有线段围成的面积, 称为”期望总体代价”. 我们希望面积越小越好.